Machine Learning and AI can be a daunting domain. There is a lot of advanced math, new technical terms, and low level hardware that a typical programmer may not be familiar with. Some of the things an ‘AI system’ can do can seem like magic. The scale of some systems can be enormous. Models can have billions of nodes or parameters.
I’m here to tell you it’s not that complicated. We don’t need advanced math or specialized hardware to do machine learning and build an AI system. Like any other discipline, we may need those things to build the ‘best’ AI system, but we don’t need them to build a ‘useful’ AI system. We’re going to learn the fundamental building blocks and compose them together to make interesting things. Small building blocks, combined together in different ways and in large quantities, produce complex and interesting systems.
As a programmer, even if you are not responsible for any machine learning tasks, you will need to interact with folks who do. It is important to understand the fundamentals of machine learning so that it can be applied to the systems you build, even if you don’t directly do any machine learning yourself. There are many different ways to build a system to solve the same problem. Some are better than others. Eventually your system needs to be optimized. Machine learning is a great tool for optimizing systems. Optimizability is an important property of software systems, just like testability and observability. Other people are often responsible for monitoring or testing your the system that you build, and it is your responsibility to make it possible (and easier) for them to their jobs. Just as you need to understand the fundamentals of software testing to make a system testable, you also need to understand the fundamentals of machine learning to make a system optimizable, so that folks who are responsible for those activities can do their jobs well.
The Building Blocks of AI
Let’s start by defining some terms.
A function transforms inputs into outputs. This is the core of everything we are going to do. When we talk about a function here, we will not be using the strict mathematical definition. We will lean more towards a function in a programming language. Sometimes this is given to you. There is some existing process or system that already exists that you need to work with.
Machine Learning is the process of finding the inputs to a function that produce the best outputs. Evaluating which outputs are ‘best’ can be subjective and complicated.
AI is a very broad term, and highly debatable. For our purposes, an AI System is a function which changes its outputs in response to its inputs. Internally, Machine Learning is used to effect that change. Machine Learning is just one part of an AI System. The system may include memory (such as a database), interfaces with other devices (such as a camera, microphone, or computer screen), interfaces with other systems (such as an API), algorithms to perform certain kinds of tasks (like generating the text of a poem) and more. These other components are all important for a full AI System to do something interesting, but the part that makes it an AI System and not just a System is the fact that it ‘learns’. So that’s the part we’re going to focus on.
What does it mean for a system to ‘learn’? We’re going to avoid the philosophical rabbit hole and keep things focused on functions. A system is a function; it transforms inputs to outputs. If the same inputs always produce the same outputs, the system is static. If the same inputs produce different outputs over time, the system is dynamic. If the manner in which the outputs change is related to the manner in which the inputs are supplied, the system is adaptive. If the same inputs produce BETTER outputs over time, we can say that the system learns. To have a system that learns, it must be dynamic, it must be adaptive, and there needs to be a measurable evaluation of its performance. Now let’s get back to the mechanics of learning.
As I said above, Machine Learning is the process of finding the inputs to a function that produce the best outputs. So here are the core pieces of machine learning:
- A function which takes inputs and produces outputs (The Model)
- A way to compare outputs to each other to determine which is ‘best’ (The Cost Function)
- A method to search for the inputs that produce the ‘best’ outputs (The Optimization Algorithm)
All three of these core pieces should be in the wheel house of the average programmer. We write functions all the time. We compare things all the time with >, <, == or implementing an interface like Comparable. We write search methods all the time, like finding the element in a collection with a particular ID.
We’re going to gradually build on these core pieces.
Training a Model
One of the common phrases in Machine Learning is “training a model”. We can rephrase that in terms of our core pieces above. A model is a function. It maps inputs to outputs. We want to train it to produce better outputs. How do we train it? We adjust the inputs, and measure the quality of the outputs, via the cost function. We keep feeding it more inputs (searching) to find the ones that work the best. Rearranging that to be more like we would implement it, we would:
- Loop through our possible inputs
- For each input, call the model function.
- Call the cost function with the output of the model function.
- Compare that to previous outputs. If it’s the best, keep it. If not, discard it.
- If we have exhausted our inputs or found a sufficiently good output, quit. Else continue looping.
An Example
Let’s walk through an example with a simple problem. In Machine Learning, the complexity of a problem often relates the number of different inputs, and the number of possible values for each input. The fewer inputs there are, the fewer possible ways there are to combine them together, which means the model is smaller. The fewer possible values for each input there are, the smaller the input space is, which means we don’t need to search through as many values, which means we can use naive search techniques, like exhaustive search. With that in mind, we’re going to do an example with a single parameter, which has a small fixed set of possible values.
Here is our (somewhat contrived) scenario, which I promise will get more interesting later. You have a 2d game with a cannon and a target. There are 5 settings for the cannon’s angle that you can choose from. Which setting will get you closest to the target? Something like this diagram:
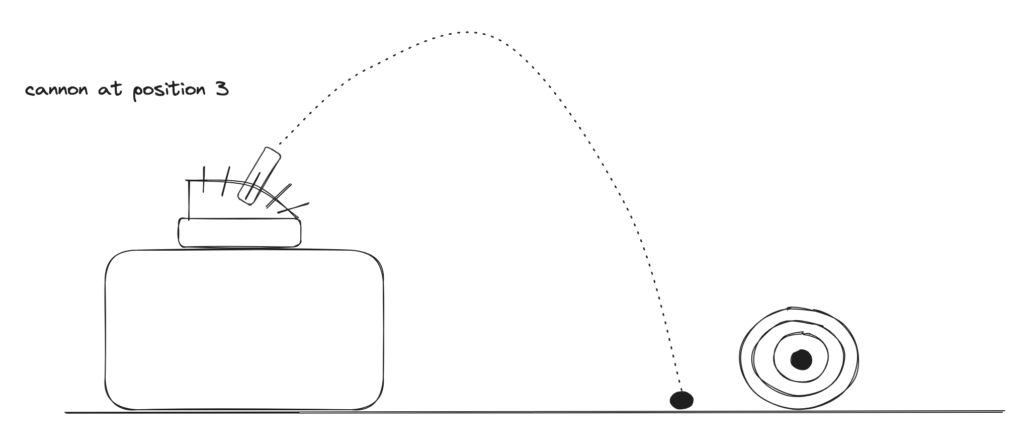
Let’s frame this as a machine learning problem. Our inputs are the 5 possible positions. Our model function in this case is ‘given’ to us – firing the cannon. Our output is the distance from the target. Our search method will be exhaustive search. Here is what that will look like in pseudocode:
function learn() {
inputs = [1, 2, 3, 4, 5] // positions of the cannon
bestInput = inputs[0]
closestDistance = MAX_FLOAT
// search through the inputs
foreach input in inputs {
// invoke the model function
distance = fireCannon(input)
// compare the output
if (distance < closestDistance) {
// save the best output so far
bestInput = input
closestDistance = distance
}
}
// return the model parameter that achieved the best output
// along with the value of the best output
return (bestInput, closestDistance)
}Congratulations! You did it! You did machine learning!
That was too simple, you say. We just tried everything and found the best way to do it. We sure did. That’s a powerful concept we’re going to take with us. It is a powerful mindset that we need to adopt. As problems get more complex, we won’t be able to try everything. But we are going to try a lot of possibilities. This is a basic recipe for success in many real world domains. Chefs and mixologists try many combinations of ingredients in different quantities to find the best flavors. Bodybuilders try many different workout and diet variations to find the best way to build muscle. Thomas Edison tried a whole lot of different ways to make a lightbulb to find one that worked. It all follows the same basic pattern. Iterate through the inputs, feed them into the model, measure the outputs, and repeat.
Machine Learning is all about searching. Sometimes we can be clever in how we search, and find the best inputs faster. Sometimes we just need to search for a long time. We’re going to build on this basic pattern to make progressively more complex machine learning programs.
Optimizability
In the context of applying machine learning to systems, optimizability describes how much you are able to optimize the parameters of a function. How good can you make the output by changing the parameters? In the above example, fireCannon is somewhat optimizable. We can choose different inputs to get closer to the target. What makes a function more or less optimizable? Precision and determinism. Let’s talk about determinism first.
In the fireCannon example, whenever you call the function with a given input, it will always yield the same output. The function is deterministic. There is no randomness or state-dependent behavior. We can reliably map inputs to outputs to evaluate which inputs yield better outputs.
With fireCannon, the input is a small fixed set of possible values. They could be an angle from 0 to 90 degrees. That would be a more precise input control. More precise means more possible values to choose from, which means more possible outputs, which usually means we can get better outputs. The 5 inputs we can choose from in the example may not actually hit the target, you might just get ‘as close as you can’. But if you can choose any angle to fire the cannon from, you can hit the bullseye.
There are also some fixed parameters that the fireCannon author has ‘hidden’ from us. Since we are modeling firing a cannon, there will be some model of gravity, and some representation of the force at which the cannon is fired. If we are modeling a real situation, some things may be out of our control and should be treated as such. In this case, gravity is probably fixed. But the force used to fire the cannon could arguably be within our control. We could make the fireCannon function more optimizable by exposing the firing force as an additional parameter to the function.
This is what you need to think about when you write your functions and build your systems. Which properties of the system are allowed to change, and do they affect the output? If so, they should be exposed, so that they can be controlled, so that they can be optimized, so that our systems can be better.
What’s Next?
In Part 2, we’re going to take a deeper look at the core pieces of Machine Learning – the model function, the cost function, and the search algorithm.